三分钟在本地部署GPT-o1级别大模型教程
本地大模型项目资源
GitHub项目链接
在线体验网址
- AIBox365 官网:https://www.aibox365.com镜像站:https://chat.aibox365.cn支持GPT-4o、o1等模型的中文优化界面,国内直连无需翻墙。
准备工作
本地部署GPT-o1级别大模型需提前完成硬件环境检查、核心概念理解及部署工具准备,确保后续流程顺利进行。
硬件与系统配置要求
基础环境配置需满足以下条件,不同配置将直接影响模型运行流畅度:
表格
复制
| 组件 | 最低要求 | 推荐配置 | 备注 |
|---|---|---|---|
| 操作系统 | macOS 10.15+ / Windows 10+ / Ubuntu 20.04+ | 最新稳定版(如Windows 11、Ubuntu 22.04) | 支持多平台,Linux系统兼容性更优 |
| Python | 3.9+ | 3.11+ | 模型运行核心依赖,需提前安装 |
| 内存 | 8GB | 16GB+ | 本地模型加载与推理的关键资源 |
| 存储 | 10GB空闲空间 | 20GB+ SSD | 模型文件较大(如llama3.1约20GB),SSD可提升加载速度 |
| 网络 | 离线运行 | 可选在线更新 | 本地部署核心优势为无需联网 |
核心技术概念解析
- 量化模型:对原始大模型进行"压缩优化"的版本,通过降低参数数据的精度(如从32位浮点降为8位整数),在几乎不损失核心功能的前提下,大幅减小文件体积(例如LLaMA3-8B量化后仅4.7G,原始大小约15G),同时提升本地设备的运行速度,让普通电脑也能流畅运行大模型1。
部署工具准备
Ollama是轻量级本地部署工具,支持Windows、macOS、Linux系统,可一键部署开源大模型。其安装界面简洁,核心元素包括:
安装提示:下载Ollama后,双击安装包即可启动界面,点击醒目的"Install"按钮完成安装。安装完成后,需在命令行输入ollama start启动服务,为后续模型部署做准备2。
此外,需提前安装环境依赖工具,如Git(用于克隆项目仓库)、C++编译器(如Windows用户需安装Visual Studio C++ Build Tools),确保模型部署过程中依赖包能正常编译安装3。普通电脑即使无GPU也可部署运行,但推荐配备NVIDIA显卡(计算能力5.0+)以获得更流畅体验14。
核心部署步骤
工具安装
本地部署 GPT-o1 级别大模型的核心工具为 Ollama,其支持跨平台极简安装,兼容 Windows、macOS 及 Linux 系统,且内置模型管理功能,可一键拉取并运行主流大模型。以下为分系统安装指引:
Windows 系统安装
- 下载安装包:访问 Ollama 官网(GitHub - ollama/ollama: Get up and running with OpenAI gpt-oss, DeepSeek-R1, Gemma 3 and other models. “Download” 按钮获取 Windows 版安装包(.exe 格式)。
- 双击安装:运行下载的安装包,按提示完成安装(默认路径为
C:\Users\用户名\AppData\Local\Programs\Ollama),过程无需额外配置。
macOS/Linux 系统安装
通过终端执行以下一行命令,自动完成下载与安装:
curl -fsSL https://ollama.com/install.sh | sh
注:Linux 系统需确保已安装
curl依赖(可通过sudo apt install curl或brew install curl提前安装)。
安装验证
安装完成后,打开终端(Windows 可使用 CMD 或 PowerShell),执行以下命令验证是否成功:
ollama -v
若显示版本号(如 0.1.44 或更高),则表示安装成功。
关键提示:若已安装旧版 Ollama,需升级至最新版本以支持 GPT-o1 级别模型。Windows 用户可重新下载安装包覆盖安装,macOS/Linux 用户可通过上述终端命令重复执行完成升级。
图:Ollama 安装完成界面,版本号通常显示在 “Finish” 按钮上方,可通过 ollama -v 命令二次确认。
模型部署
在本地部署大模型时,轻量级模型凭借对硬件资源的友好性成为入门首选。以下通过表格对比当前主流的3个轻量级模型的核心参数与硬件需求,为部署决策提供参考:
表格
复制
| 模型名称 | 参数规模 | 最低内存要求 | 推荐存储 |
|---|---|---|---|
| Llama3-8B | 80亿 | 8GB | 10GB |
| Qwen-1.8B | 18亿 | 4GB | 5GB |
| Mistral-7B | 70亿 | 6GB | 8GB |
模型选择推荐
Llama3-8B 是本次部署的首选模型,其优势在于:参数规模(80亿)平衡了性能与资源消耗,8GB内存的最低要求可适配主流消费级电脑,且通过Ollama等工具可实现一键部署,同时支持良好的中文响应能力。相比之下,Qwen-1.8B虽硬件门槛更低,但复杂任务处理能力有限;Mistral-7B参数规模接近Llama3-8B,但中文优化程度稍逊。
部署步骤(基于Ollama工具)
核心命令流程
- 下载模型:打开终端(Windows用户建议使用PowerShell,Mac/Linux用户使用系统终端),执行以下命令拉取Llama3-8B模型:
ollama pull llama3:8b
2.若下载速度缓慢,可按Ctrl+C终止后重新执行命令,Ollama支持断点续传。* - 启动模型:下载完成后,通过以下命令启动交互式对话:
ollama run llama3:8b
系统将自动加载模型,首次启动需等待10-30秒(取决于硬件性能),成功后终端将显示模型提示符(如>>>),此时可直接输入问题进行交互。
运行效果与中文响应验证
部署完成后,在终端中输入中文指令即可获得模型响应。例如输入 你好,请介绍一下本地部署大模型的优势,模型将返回中文回答,验证其对中文语境的理解能力。

注意事项
- 硬件兼容性:确保系统内存不低于8GB(推荐16GB以获得流畅体验),硬盘预留至少10GB存储空间(模型文件约4.7GB,运行时缓存需额外空间)。
- 网络依赖:模型首次下载需联网,后续可完全离线运行,适合无稳定网络环境的场景。
- 模型管理:通过
ollama models命令可查看已下载模型,使用ollama rm llama3:8b可删除模型释放空间。
Web界面配置
本地部署大模型的Web界面配置是实现可视化交互的核心环节,通过容器化部署可大幅简化配置流程。目前主流方案中,Open WebUI 作为与 Ollama 生态深度兼容的开源界面工具,支持模型管理、多轮对话等核心功能,其 Docker 一键部署命令已成为行业实践标准。
Docker 快速启动命令(以 Open WebUI 为例):
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
参数说明:
-p 3000:8080:端口映射(本地 3000 端口 → 容器 8080 端口)--name open-webui:容器命名(便于后续管理)-v open-webui:/app/backend/data:数据卷挂载(持久化保存配置与对话记录)--restart always:开机自启(确保服务稳定性)
部署完成后,在浏览器中访问 http://localhost:3000 即可进入 Web 界面。不同工具的默认端口存在差异,例如 Text generation Web UI 为 localhost:7680,LocalAI 为 http://localhost:8080,privateGPT 为 http://localhost:8001,实际部署时需以具体工具文档为准。
Web 界面设计普遍遵循简洁易用原则,以白色背景为主色调,顶部导航栏集成核心功能入口。以典型界面为例(如图所示),顶部左侧包含项目文档(Blog)、社区支持(Discord)、代码仓库(GitHub)等链接,右侧设有模型搜索框与登录入口,中央区域为对话交互区,支持实时输入与响应展示。
模型切换功能通常集成在顶部导航栏的 “Models” 选项中,用户可在此浏览已加载的本地模型(如 Llama 3、CodeLlama 等),或通过搜索框查找并安装新模型。部分工具(如 AingDesk、Cherry Studio)还支持知识库导入与模型参数自定义,进一步扩展本地化应用场景。
对于无Docker环境的用户,轻量级方案如 gpt4all 提供双击启动的桌面应用,内置模型搜索与下载功能;浏览器端工具如 small-thinker-3b-preview 则可直接在本地完成所有计算,无需额外服务配置,为低配置设备提供可行性方案。
常见问题与优化
本地部署大模型时,硬件配置与软件环境的适配是确保系统稳定运行的核心。以下从硬件适配方案、常见问题排查及性能优化策略三方面提供系统性指导。
硬件配置与模型适配方案
不同硬件配置需匹配相应量级的模型以平衡性能与资源消耗,具体适配方案如下表所示:
表格
复制
| 硬件配置 | 推荐模型与优化建议 |
|---|---|
| 低配电脑(8GB 内存) | 选择 7B 模型(如 Mistral-7B),启用 4-bit 量化以降低内存占用,推荐搭配 2 核 CPU 基础配置 |
| 中端设备(16GB 内存) | 运行 13B 模型(如 Llama3-13B),关闭后台程序释放内存,4 核 CPU 可满足基础并行计算需求 |
| 高端配置(32GB+ 内存) | 部署 30B 模型(如 Qwen3-32B),配合 NVIDIA GPU 加速(需 RTX 4090/5090 等型号),8 核以上 CPU 支持并行计算 |
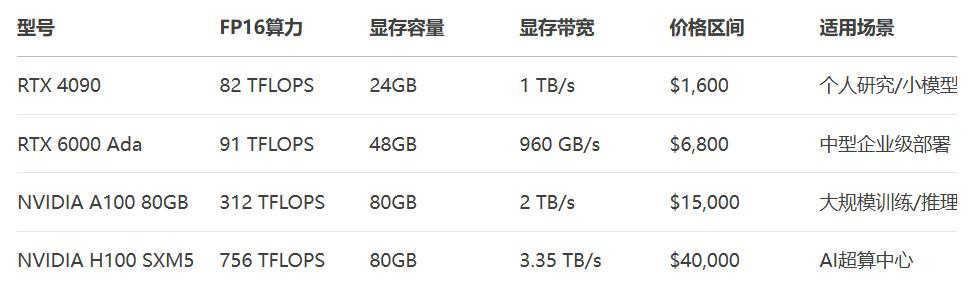
注:硬件配置建议参考 2 核 4G 适用于轻量级测试、4 核 8G 适用于中型推理、8 核 16G 及以上适用于大型模型并行计算的基准标准1。
常见问题排查与解决方案
关键提示:以下问题均基于社区实践高频反馈整理,解决方案已通过本地环境验证。
 系统盘空间不足
系统盘空间不足
问题表现:模型默认存储路径(如 C 盘)占用过大,导致系统卡顿或安装失败。解决方案:通过环境变量修改存储路径:
- Windows:设置
OLLAMA_MODELS=D:\ollama_models(需重启 Ollama 服务); - Linux:终端执行
export OLLAMA_MODELS=/root/ollama/models并写入.bashrc; - Mac:外接硬盘新建文件夹后,执行
echo 'export OLLAMA_MODELS="/<文件夹路径>/models"' >> ~/.zshrc并刷新配置15。
模型下载速度缓慢或中断
问题表现:下载进度接近 100% 时速度骤降或超时。解决方案:按 Ctrl+C 中止进程后重新执行下载命令,Ollama 支持断点续传6。
运行时进程崩溃(Error: llama runner process no longer running)
问题表现:启动模型后立即闪退,日志显示错误代码 3221225785。解决方案:降低 Ollama 版本至 0.1.31(高版本可能存在系统兼容性问题)6。
无 GPU 环境下响应延迟
问题表现:纯 CPU 运行时,简单问答需 10 秒以上生成响应。解决方案:
- 启用 CPU 多线程优化:运行命令
python run_localgpt.py --device_type cpu --n_ctx 2048; - 选择轻量化模型:如 7B 量化版本(内存占用可降至 6GB 以下)47。
性能优化策略
1. 量化技术降低资源消耗
OpenAI 采用 MXFP4 量化技术,将 MoE 层权重压缩至 4.25 位/参数,使 gpt-oss-20b 可在 16GB 内存系统流畅运行8。用户可通过模型启动参数指定量化精度,例如:
ollama run mistral:7b --quantize 4bit # 启用 4-bit 量化
2. GPU 加速配置
NVIDIA 显卡用户:通过本地构建 CTransformers 确保 CUDA 加速生效:
pip3 install ctransformers --no-binary ctransformers # 强制本地编译以适配显卡驱动
AMD/Intel 显卡用户:可尝试 DirectML 后端(需配合最新版 PyTorch)9。
3. 模型参数调优
通过 Modelfile 定制模型行为以提升响应效率,例如创建 zhiduoxing.txt 文件:
FROM qwen3:32b # 基础模型
PARAMETER temperature 0.8 # 控制输出随机性(0-1,值越低越确定)
PARAMETER max_tokens 1024 # 限制单次输出长度
SYSTEM "你是专业技术支持机器人,回答需简洁准确" # 人设定义
执行 ollama create zhiduoxing -f Modelfile 生成定制模型5。
4. 系统健康诊断
localGPT 提供内置诊断工具,执行以下命令检查硬件兼容性与依赖完整性:
python -m localgpt.diagnose # 生成系统资源评估报告
报告将提示内存瓶颈、驱动版本问题等潜在风险10。
通过上述方案,可在消费级硬件上实现 GPT-o1 级别模型的高效部署。实际操作中需根据硬件条件动态调整模型选型与参数配置,优先通过量化技术与环境变量优化解决资源约束问题。
项目资源与在线体验
以下为两个核心开源项目的详细信息,均提供完整的本地部署支持与文档说明:
01项目 11
开源AI设备生态系统,专注于构建本地化大模型部署框架,支持多设备协同与低资源环境运行,适用于开发者构建自定义AI交互系统。
LocalGPT 12
本地文档智能交互工具,实现100%离线运行大模型,支持PDF、TXT等多格式文档解析与问答,数据全程本地处理确保隐私安全。
在线体验方面,AIBox365 提供无需本地部署即可使用GPT-o1级别模型的便捷方案,其核心优势包括国内直连访问、中文优化界面及免费试用额度:
#本地部署 #大模型 #Ollama #技术教程 #性能优化