零代码爬虫神器Spider Flow:3步轻松抓取网页数据
Spider Flow简介
还在为不会写代码却需要抓取网页数据而发愁?对于设计师、运营人员、学生等非技术人群来说,Spider Flow 就像一位“技术小白的爬虫救星”——无需编写一行代码,只需像搭积木一样拖拽节点,就能轻松搞定网页数据抓取12。这款由国内团队开发的零代码工具,重新定义了数据采集的门槛,让复杂的爬虫任务变得像画流程图一样简单。
三大核心亮点让数据抓取化繁为简
![]() 开源免费:作为 GVP 项目,源码托管在 GitHub 和 Gitee,8.1K Star 见证其开源价值,无需付费即可使用全部功能34。
开源免费:作为 GVP 项目,源码托管在 GitHub 和 Gitee,8.1K Star 见证其开源价值,无需付费即可使用全部功能34。
![]() 图形化操作:通过流程图界面拖拽节点,左侧选功能、中间连流程、右侧配参数,全程可视化设计爬虫逻辑,告别代码编辑器56。
图形化操作:通过流程图界面拖拽节点,左侧选功能、中间连流程、右侧配参数,全程可视化设计爬虫逻辑,告别代码编辑器56。
![]() 企业级能力:支持动态网页、复杂数据处理,自带 debug 功能和日志记录,从简单列表到企业级数据抓取需求都能满足78。
企业级能力:支持动态网页、复杂数据处理,自带 debug 功能和日志记录,从简单列表到企业级数据抓取需求都能满足78。
无论是电商商品信息、行业报告数据,还是学术研究资料,Spider Flow 都能帮你快速获取。想亲自体验零代码爬虫的便捷?访问官方网站 https://www.spiderflow.org/ 即可开始探索。

核心特点解析
Spider Flow 之所以能成为零代码爬虫领域的佼佼者,核心在于其精准解决了传统数据抓取中的四大痛点。通过可视化操作、多维度提取、智能抗反爬与无缝数据导出的全链路设计,让非技术人员也能轻松掌握数据采集能力。
零代码可视化操作:告别编程门槛
传统 Python 爬虫需要掌握复杂的代码逻辑和网页解析知识,动辄上百行代码让新手望而却步。Spider Flow 采用 图形化流程设计,用户只需拖拽左侧功能节点(如“抓取首页”“提取数据”“输出结果”),通过黑色箭头连接节点即可完成爬虫配置,整个过程像搭积木一样直观19。无论是市场人员监控竞品价格,还是学生收集研究数据,无需编写一行代码就能实现复杂的数据抓取逻辑。
零代码优势:无需掌握 Python、Java 等编程语言,通过拖拽节点即可完成从网页请求到数据存储的全流程配置,让市场、运营等非技术岗位也能独立完成数据采集。
全场景数据提取:适配复杂网页结构
不同网页的数据结构千差万别,单一提取方式往往难以应对。Spider Flow 提供 XPath、CSS 选择器、正则表达式、JsonPath 等多种提取工具,支持混搭使用以应对复杂场景1011。例如,电商商品页可用 CSS 选择器定位价格标签,新闻网站的动态内容可用 XPath 提取正文,而社交媒体的评论数据则可通过正则表达式清洗格式。这种灵活性使其能覆盖电商价格监控、舆情分析、学术文献采集等多样化需求,无论是京东的动态价格、微博热搜的实时榜单,还是淘宝评论的用户反馈,都能精准提取12。
抗反爬与自动化:解决新手“爬取失败”难题
新手爬虫常因 IP 封禁、动态页面加载失败等问题半途而废。Spider Flow 内置 IP 代理池插件,可自动切换 IP 地址并随机伪装请求头,降低被网站封禁的风险;搭配 Selenium 插件,能轻松处理 JavaScript 动态渲染的页面(如 Ajax 加载的商品评论)113。此外,系统支持 Cookie 自动管理和多线程爬取,可实现 7×24 小时稳定运行,无需人工值守即可完成大规模数据采集。
反爬解决方案:内置 IP 代理池插件自动切换访问节点,搭配 Selenium 插件解析 JavaScript 动态渲染内容,解决 90% 新手遇到的“爬取失败”问题。
一键数据导出:省去手动整理步骤
爬取数据后手动整理成表格或导入数据库,往往耗费大量时间。Spider Flow 支持将采集结果 直接导出为 Excel、CSV 文件,或一键对接 MySQL、MongoDB、Elasticsearch 等数据库,实现数据采集-存储的无缝衔接1415。用户无需手动复制粘贴,即可将京东商品价格、微博舆情数据等直接用于分析报告或业务系统,大幅提升工作效率。
三步上手使用教程
无需复杂编程知识,只需简单三步,即可快速掌握 Spider Flow 的使用方法,轻松开启数据抓取之旅。
快速部署(2分钟完成)
部署过程极致简化,即使是技术新手也能轻松完成。首先,访问 Spider Flow 官方 GitHub 仓库(https://github.com/ssssssss-team/spider-flow)下载源码,将其解压到本地目录。接着,使用 IDEA 打开项目并运行,待项目启动后,在浏览器中输入 localhost:8088 即可访问登录界面。整个过程无需配置复杂的数据库或环境变量,真正实现“下载即使用”。
(配图:Spider_Flow_使用示例.png,标注访问地址 localhost:8088 的登录界面截图)
流程设计(3步拖拽)
零代码的核心优势在此体现,通过简单的拖拽操作即可完成爬虫流程设计:
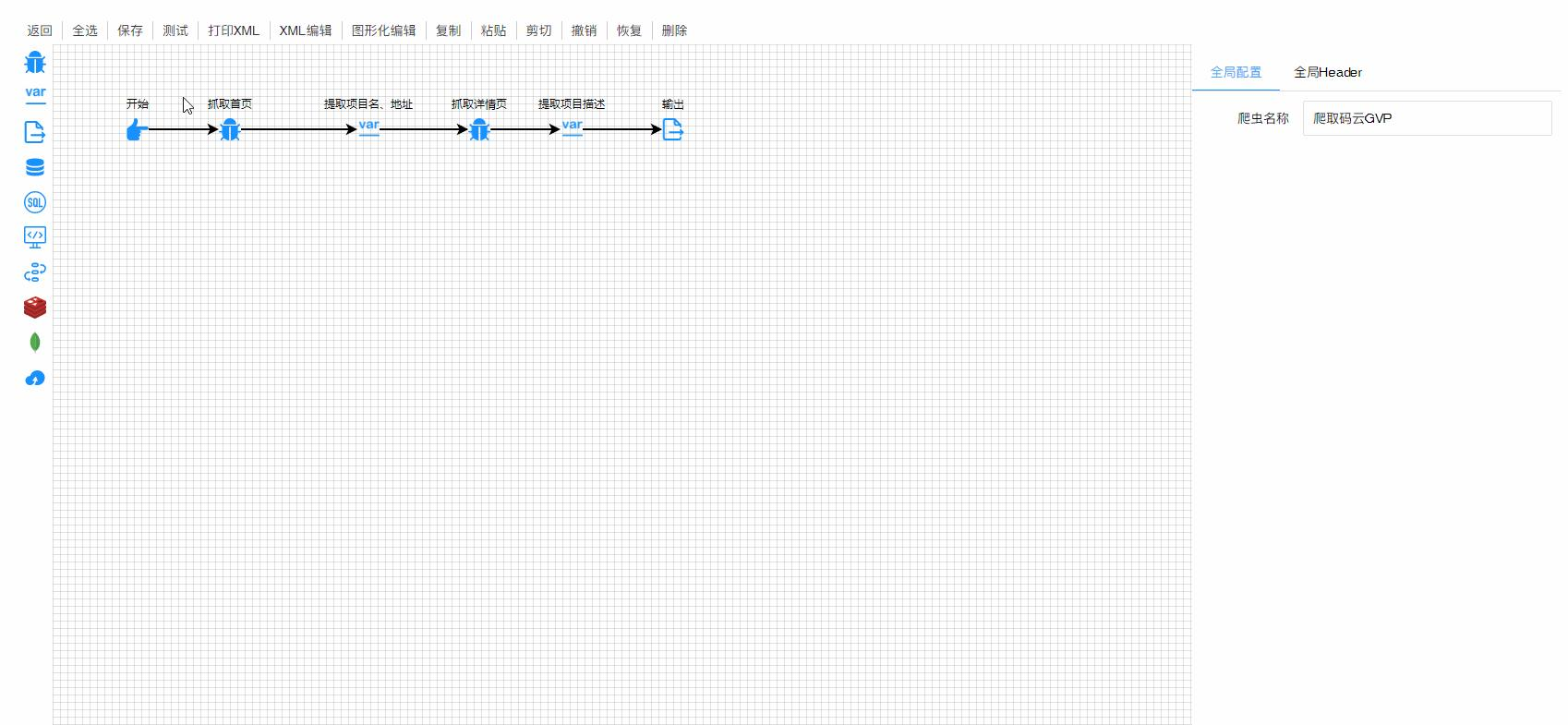
第一步:初始化流程 - 从左侧组件栏拖入“开始”节点,作为流程的起点;紧接着拖拽“抓取节点”并与“开始”节点连接,在“抓取节点”配置面板中输入目标网页的 URL,如需要爬取的商品列表页或新闻资讯页。
第二步:提取目标数据 - 添加“提取节点”并连接至“抓取节点”,在该节点中选择 CSS 选择器工具,通过点击目标网页元素自动生成定位规则,精准提取标题、价格、日期等所需数据字段。
第三步:配置输出方式 - 最后拖入“输出节点”并连接,选择数据保存格式(如 CSV、JSON 或数据库),以 CSV 为例,设置文件保存路径后即可完成流程设计。
(配图:Spider_Flow_使用示例_1.gif,演示从节点拖拽、配置到连接的完整流程)
运行与查看结果
完成流程设计后,点击流程画布上方的“测试”按钮即可启动爬虫。系统会实时显示爬取进度,运行结束后,在“输出”节点的详情面板中可直接查看结构化的数据表格,包含爬取时间、字段名称及对应数值。此外,Spider Flow 还支持“定时任务”功能,设置每日或每周的执行时间,即可实现 7×24 小时无人值守的自动数据采集,无需手动重复操作。
通过以上三步,即可从零基础快速上手 Spider Flow,无论是市场调研、竞品分析还是数据监控,都能高效完成数据抓取需求。
实用场景与工具链接
Spider Flow 凭借零代码特性,已深度融入多类实际工作流,以下为三个高频应用场景及核心价值:
学生论文数据采集:无需编写代码即可批量抓取学术数据库文献摘要、期刊影响因子等数据,快速构建论文实证分析的原始数据集,大幅缩短数据收集周期。运营热点追踪:实时监控微博、知乎等平台话题热度变化,自动提取高互动量内容的关键词与传播路径,助力运营团队精准把握用户关注点。电商竞品分析:定时爬取淘宝、京东等平台竞品的价格波动、销量趋势及用户评价标签,生成可视化对比报告,为产品定价与功能优化提供数据支撑。
作为开源项目,Spider Flow 的源码完全开放(GitHub 星标数超 10k),开发者可通过提交 Issue 或 PR 参与功能迭代,例如贡献自定义解析规则或扩展数据源适配能力,共同完善工具生态。
核心资源汇总
使用提示:新手建议优先通过官网「快速入门」板块,结合示例模板(如「爬取码云 GVP 项目信息」)熟悉操作流程,插件安装后需在「全局配置」中启用对应功能模块。