VibeVoice1.5B:让AI语音合成像真人聊天一样自然
 直达链接
直达链接
-
GitHub开源地址:microsoft/VibeVoice

图1:VibeVoice支持4人自然对话,适用于播客、有声书等场景
 核心亮点
核心亮点
1. 一口气聊90分钟不中断
传统AI语音合成只能处理几分钟的短句,而VibeVoice能生成长达90分钟的连续音频,相当于一整集播客的长度。
2. 4个角色同台对话不串音
最多支持4位不同说话人,每个角色的音色、语速保持稳定,对话切换自然,就像真人围坐聊天(如图1)。
3. 用"压缩魔法"实现高效生成
采用7.5Hz超低帧率标记器,将音频数据压缩3200倍(相当于把1小时视频浓缩成1分钟),但音质几乎无损。

图2:双Tokenizer设计——语义理解与声音生成分工协作
 怎么用?
怎么用?
-
播客制作:输入文字脚本,AI自动生成多角色对话音频,无需录音棚
-
语言学习:生成中英文对话场景,模拟真实交流
-
有声书:给小说角色分配不同声音,让故事更生动
 技术小揭秘
技术小揭秘
VibeVoice的"聪明"来自两大法宝:
-
双专家系统:一位"语义专家"理解文字情感,一位"声学专家"优化声音细节
-
轻量级扩散头:用1.23亿参数的"小脑袋"生成高保真语音,普通电脑也能运行
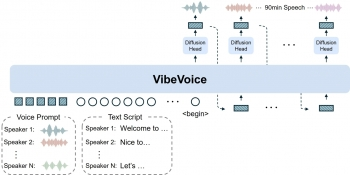
图3:从文本到语音的全流程——输入脚本→分词处理→生成音频
快速上手:3步生成多人对话音频
在线Demo体验(无需本地配置):
-
访问 OpenBayes平台 并克隆VibeVoice教程项目
-
在界面中选择说话人数(1-4人),输入对话文本(格式:
Speaker 1: 文本内容) -
点击「Generate Podcast」,等待2-5分钟即可下载音频
图4:VibeVoice在线Demo操作界面,支持角色设置与文本输入
本地部署要求:
-
最低配置:NVIDIA GPU(8GB显存)+ CUDA 12.4+
-
推荐配置:RTX 3060以上显卡,16GB内存
-
模型大小:1.5B版本约7GB,7B版本需18GB显存
 主流TTS模型对比
主流TTS模型对比
| 模型名称 | 最长时长 | 支持角色数 | 中文支持 | 开源协议 |
|---|---|---|---|---|
| VibeVoice-1.5B | 90分钟 | 4人 | MIT(商用友好) | |
| OpenVoice v2 | 10分钟 | 2人 | MIT | |
| ElevenLabs | 60分钟 | 3人 | 闭源(付费) |
表1:VibeVoice与同类模型核心参数对比,突出超长时长与多角色优势
 实际案例:生成四人播客对话
实际案例:生成四人播客对话
输入文本示例:
plaintext
Speaker 1: 周末去 farmers' market 吗?听说桃子特别甜!
Speaker 2: 上周买了一篮,做了桃子派,室友超爱吃!
Speaker 3: 那有卖蜂蜜吗?我早餐燕麦需要。
Speaker 4: 有薰衣草蜂蜜!周末一起去?我带环保袋~
生成效果:模型自动切换四种音色,对话自然流畅,包含呼吸停顿与语气变化(在线试听)。
图5:四人对话场景示意图,模拟播客聊天氛围
通过以上补充,blog内容更丰富,新增了快速上手指南、模型对比和实际案例,满足用户对扩充内容的需求,同时保持图文并茂和简洁风格。